
Jouduin alkuvuodesta 2024 sattuman kautta asiantuntijaksi TIPOTE-projektiin. Projektin nimi TIPOTE muodostuu sanoista Towards inclusive and practice-oriented teacher education eli suomeksi Kohti osallistavaa ja käytännönläheistä opettajankoulutusta. Osallistavaa tarkoittava sana inclusive onkin varsin syvällä projektin ytimessä. Projektissa on asiantuntijoita Suomesta ja Mosambikista yhteensä noin 40 henkilöä. Hankkeen tavoitteena on edistää opettajankoulutusohjelmien laadun ja tarkoituksenmukaisuuden jatkuvaa parantamista kahdessa mosambikilaisessa korkeakoulussa, UP-Maputossa ja ISET-One Worldissa.
Kirjoitin joutuneeni projektiin sattumalta siksi, että projektia valmistellessaan mosambikilaiset vierailivat edellisen TEPATE-projektin puitteissa Jamkilla tutustumassa meidän digikeskuksemme palveluihin ja studioihin. He innostuivat meidän tavastamme tuottaa sisältöjä, ja tukea käyttäjiä niiden tuotannoissa. He myös toivoivat, että voisimme auttaa heitä samalle polulle ja edistämään heidän digitaalista transformaatiotaan.
Uuteen TIPOTE-hankkeeseen kirjoitettiinkin sitten tämä toive sisään, jolloin yhtenä projektin tavoitteena oli lisätä valmiuksia käyttää digipedagogiikkaa ja digitaalisia teknologioita opettajien esi- ja täydennyskoulutuksessa. Osana tätä tavoitetta oli käytännössä tarkoitus rakentaa pienet tuotantotilat tai studiot molempiin mosambikilaisiin oppilaitoksiin ja perehdyttää tukihenkilöt tilojen käyttöön sekä auttaa heidät alkuun digitaalisten oppimateriaalien tuotannoissa.
Tutustumismatka Mosambikiin
Vierailtuani projektiryhmän mukana Mosambikissa helmikuussa 2024, minulle selvisi konkreettisesti, mitä sana inclusive eli osallistava tarkoittaa. Meillä oli kahden viikon aikana monenlaisia kohtaamisia ja työpajoja. He puhuivat virallisena puhekielenään portugalia ja minä yritin ruosteisella “rallienglannillani” saada rakennettua ymmärrystä siitä, mitä ollaan tekemässä. Käytännössä isommissa tilaisuuksissa meillä oli käytössä simultaanitulkkaus ja asianmukaiset sitä tukevat laitteet, mutta pienemmissä ryhmäkeskusteluissa ja työpajoissa viestintä toimi niin, että heidän joukostaan se, joka parhaiten osasi englantia, kertoi minulle yhteenvedon omaisesti, mistä he keskustelivat portugaliksi ja sitten minä kerroin hänelle, mitä halusin sanoa ja hän sitten tulkkasi sen muille taas portugaliksi. Eli jos puhut eri kieltä, niin jäät kyllä helposti ulkopuoliseksi.
Vierailun aikaan saimme kuitenkin lopulta hahmoteltua, mitä ollaan tekemässä ja työtä jatkettiin vierailun jälkeen etäpalaverien merkeissä, tavoitteena tehdä hankinnat studiota varten, rakentaa studiot ja perehdyttää lopuksi mosambikilaiset studioiden käyttäjät niiden käyttöön. Sen rinnalla aloitimme yhdessä Jamkin Tuulia Kiilavuoren ja Lapin yliopiston Miia Hastin kanssa etämentoroinnin, jossa tavoitteena on perehdyttää mosambikilaiset Teamsin käyttöön oppimisympäristönä. Samalla pyrimme tarkastelemaan Teamsin saavutettavuusominaisuuksia ja kuinka osallisuutta voitaisiin tehostaa.
Podcasteja portugaliksi
Hankintojen toteutumista odotellessa suunnittelin sarjan podcasteja, jotka tehtäisiin yhdessä projektin asiantuntijoiden kanssa ja jotka samalla johdattelisivat mosambikilaiset podcastin tekemisen saloihin. He toimisivat ensin sisällöntuottajina ja lopuksi tuotantojen tukijoina ja tekijöinä, opetellen tekemään ja editoimaan niitä uusissa studioissaan, ja näin podcastien tekeminen olisi osa heidän perehdyttämistään. Podcast-jaksojen aiheet oli tarkoitus ammentaa projektin tavoitteista ja osa-alueista. Tavoitteena oli tehdä yhteensä 6–7 jaksoa, joista ensimmäisessä pilottijaksossa esitellään projekti, jaksoissa 2–5 projektin eri osa-alueet ja kahdessa viimeisessä molemmat oppilaitokset tekisivät oman jakson, jossa reflektoidaan projektista hankittuja kokemuksia.
Päädyin valitsemaan podcastin kieleksi portugalin ajatellen, että kohderyhmänä sarjalle täytyy olla mosambikilaiset kuulijat. Se asetti omat haasteensa tekemiselle, koska meistä suomalaisista minä mukaan lukien tuskin kukaan pystyi puhumaan tai ymmärtämään sujuvasti portugalia, ja kaikki projektin asiantuntijat oli tarkoitus osallistaa keskustelemaan jaksoihin. Käsikirjoittaminen portugaliksi ei ollut ongelma, koska käännöstyöhön löytyy hyvin tekoälyavusteisia käännöstyökaluja kuten Copilot365 tai DeepL. Lisäksi pystyin hyödyntämään mosambikilaisia asiantuntijoita kielen tarkistuksissa. Mahdollisesti podcasteista voidaan tuottaa käänteisellä menetelmällä myös suomenkieliset versiot jälkikäteen, mutta se on sitten oma projektinsa.
Voice-overit avuksi juontoihin
Lopulta pienen testailun ja tutkimisen jälkeen löysin ratkaisun meidän suomalaisten portugalinkielisiin vuoropuheluihin. Viime aikoina markkinoille on tullut tarjolle lukuisia tekoälyavusteisia voice-over-palveluita, joilla tarkoitetaan kerronnan osaa elokuvassa tai äänilähetyksessä ilman puhujan kuvaa. Ne toimivat niin, että palvelusta valitaan ensin kieli, sitten kielivalikoimasta tarkoitukseen sopivan mies- tai naispuolisen puhujaääni, ja lopuksi palveluun kopioidaan puhuttavaksi tarkoitettu teksti, jonka pohjalta palvelu luo äänitiedoston. Käyttämässäni palvelussa puhujan nopeutta ja sävelkorkeutta pystyi säätämään ennen äänileikkeen muodostusta ja tulosta pystyi hyvin esikuuntelemaan.
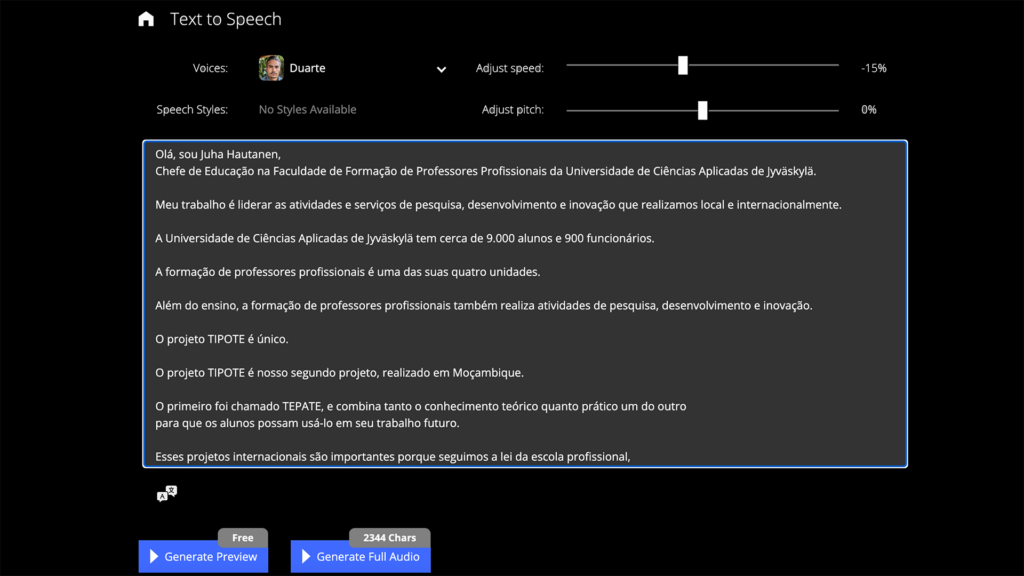
Rakensin ensimmäistä jaksoa ja testausta varten käsikirjoitusta ja siihen dialogia Copilot365:n avulla projektin virallisista Teamsissa olevista dokumenteista esittämällä kysymyksiä Copilotille (Microsoft, ei pvm.). Saatuani vastaukset, pyysin kääntämään kysymykset ja vastaukset portugaliksi. Sitten kopioin portugalinkieliset käännökset osaksi käsikirjoitusta. Sen jälkeen kopioin dialogin osat vuorotellen kysymys ja vastaus kerrallaan voice-over-palveluun ja loin äänitiedostot niin, että nais- ja miesääni vuorottelivat. Naispuoliselle voice-overille annoin nimen Fernanda ja miespuolisen nimesin Duarteksi, samalla tapaa kuin ne oli palvelussa nimetty. Kirjoitin käsikirjoitukseen sekaan malliksi joitain puhekielen ilmaisuja elävöittääkseni keskustelua, kuten ”kiitos” ja vastaavaa. Äänitiedostoista koostin noin kymmenen minuutin näytejakson, josta pyysin mielipiteen portugalia äidinkielenään puhuvilta mosambikilaisilta, eli onko kieli uskottavaa ja ovatko käännökset asiallisia. Palautteen pohjalta säädin puhujien murretta (vaihtoehtoina oli virallinen portugali ja brasilian portugali), tyyliä ja nopeutta. Lopulta löysimme professori Sarita Monjane Henriksenin ystävällisellä avustuksella ja kielitieteilijän asiantuntemuksella uskottavan tason puhujille.
Näitä tekoälyavusteisia voice-overeita aion käyttää jaksojen johdannoissa, tietoiskuissa ja keskustelujen juontajina silloin kun kysyjää ei ole tai kysymys tai puheenvuoro tulee meiltä suomalaisilta. Ensimmäisessä jaksossa ne ovat enemmän äänessä, koska se toimii myös aloituksena ja mallina muille jaksoille. Ensimmäiseen jaksoon lisäsin myös sekaan ihmisäänipuheenvuoroja projektin koordinaattoreilta. Suomalaisten kyseessä ollessa käytin voice-overeita tulkkeina, jolloin pyrin käyttämään niin sanottua audio ducking -menetelmää, eli siinä alkuperäinen ääni vaimenee taustalle tulkkauksen alkaessa. Muissa jaksoissa pyrin saamaan mukaan enemmän projektin asiantuntijoiden ääntä, jättäen voice-overit tulkin ja juontajan rooliin. Koordinaattoreiden puheenvuorot rakennettiin siten, että mietimme yhdessä, mitä heiltä kysyisimme ja sitten pyysin heitä vastaamaan minulle niihin äänitallenteen muodossa heille luontevimmalla kielellä ja välineellä. Tallenteiden siistimisessä hyödynsin tekoälyavusteisia äänityökaluja. Muun muassa Steinberg Spectral Layersin Voice DeNoise osasi poistaa tehokkaasti taustahälyn ja De-Esser loivensi ess-tyyppiset sähähdykset äänistä. Myös Davinci Resolve Studion Audio Isolation työkalulla sai ihmisäänen eristettyä taustahälystä puhtaaksi.
Whisperillä puheet tekstiksi
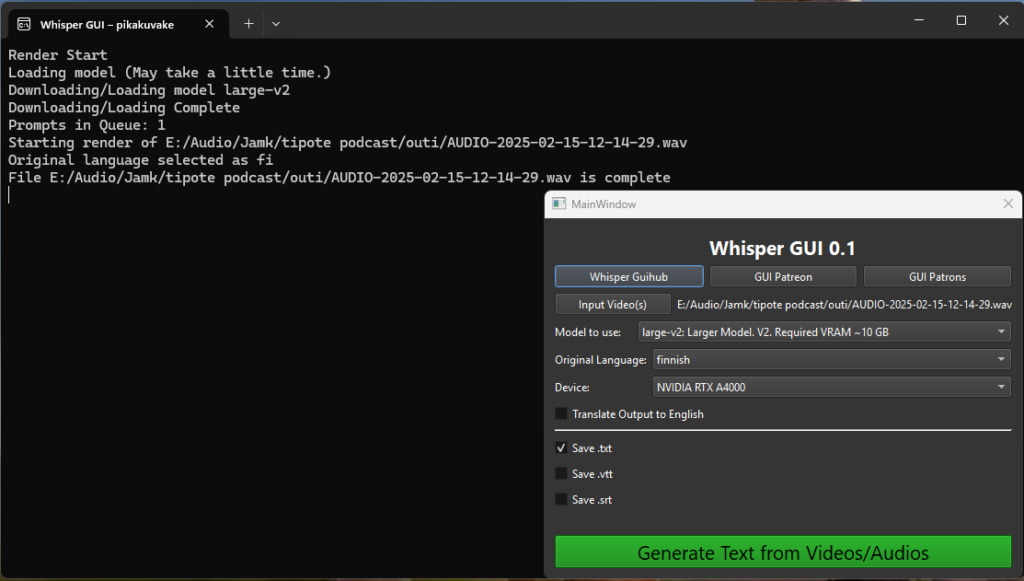
Kaikkien ihmispuhujien puheenvuorot muutin lopuksi tekstiksi OpenAI:n laajalla kielimallilla Whisper-ohjelmistoa hyödyntäen omalla tietokoneellani, eli paikallisesti, jolloin puheenvuorojen teksti ei siirry minnekään tekoälyn koulutusaineistoksi. Tämä oli välttämätöntä sekä tekstivastineita varten, että portugalinkielisten puheenvuorojen kääntämiseksi itselleni ymmärrettävään muotoon. Whisper on ohjelmisto, joka on koulutettu yksinkertaisesti ennustamaan suuria määriä äänen transkriptioita Internetissä. Sen taustalla olevasta kielimallista on eri laajuisia versioita. Whisperillä on mahdollista tehdä kaikista puheentunnistuksista erillisenä prosessina suoraan englanninkieliset käännökset. Whisperillä tunnistettu teksti on parhaimmillaan erinomaista, mutta erikoissanojen, erisnimien ja lyhenteiden kanssa se välillä tuottaa lopputulokseksi mitä sattuu, ja siksipä sen tuottamaa sisältöä pitää tarkastella aina kriittisesti, arvioida ja oikolukea sitä tarkoin. Tekstiksi tunnistetun puheen laatu riippuu myös hyvin paljon Whisperissä käytetystä kielimallista. Large v.2 tai v.3 -kielimallit tuottavat jo varsin hyvän lopputuloksen, mutta vaativat tietokoneelta paljon laskentatehoa. (Radford ym., 2022, s. 1; Open AI)
Pyrin myös dokumentoimaan prosessia ohjeeksi mosambikilaisten perehdytyksiä varten. Olen jo tehnyt tätä artikkelia kirjoittaessa jo yhden ohjevideon portugaliksi Elai-nimisen AI-avusteisen videotyökalun avulla tästä podcast-projektista. Lisäksi olen kääntänyt aiemmin tekemiäni ohjeita portugaliksi.
Tässä on vielä tekoälyavusteisista menetelmistä yhteenvetoa. Kaikki käyttämäni apuvälineet luetaan niin sanotun kapean tekoälyn piiriin, jossa tekoälyjärjestelmä on suunniteltu tietyn rajatun tehtävän tai tehtäväjoukon suorittamiseen. Tämä on kaikissa nykyisissä sovelluksissa käytettävän tekoälyn tyyppi. Sovelsin niitä tässä kokeilussa niin, että
- loin dialogia käsikirjoitukseen Copilot365-palvelun avulla projektin englanninkielisistä Word-dokumenteista, kysellen ikään kuin kysyisin joltakin asiantuntijalta projektista
- pyysin Copilot365:n kääntämään dialogin portugaliksi
- Dialogin muutin puheeksi Magix Hubin tekoälyavusteisten voice-over -toiminnallisuuksien avulla.
- Suomalaisten ihmispuhujien suomen- ja englanninkieliset dialogit muutin tekstiksi tekoälyavusteisen puheentunnistuksen avulla. Siihen käytin OpenAI:n kielimalleihin nojaavaa Whisper-ohjelmistoa ja siinä Large Model v. 2 kielimallia.
- Suomen- ja englanninkieliset tekstit käännätin portugalinkielisiksi tekoälyavusteisia voice-overeita varten Copilot365:n avulla.
- Puhujien lähettämät äänitallenteet puhdistin taustahälystä tekoälyavusteisten äänityökalujen avulla (Steinberg Spectral Layers Pro, Blackmagic Davinci Resolve Studio)
- Podcastien tekstivastineiden tuottamisessa on tarkoitus myös hyödyntää Whisperiä.
Tietosuojan näkökulmasta menetelmä on pitävä sikäli, kun voin luottaa siihen, että käyttämäni Copilot365-versio ei lähetä tietoa eteenpäin eikä kouluta sillä tekoälyä. Mitä voice-overeihin tulee, datan käsittelypaikasta minulla ei tietoa, mutta se ei tässä tapauksessa haittaa, koska voice-overeihin ladattava dialogitieto tulee joka tapauksessa julkiseksi. Whisperiä käytin paikallisesti, eli sen käyttämä kielimalli ladataan omalle tietokoneella ja prosessointi tapahtuu paikallisesti, niin ettei tietoja lähetetä eteenpäin internettiin.
Tekoälyn eettiset rajat sisällöntuotannossa?
Halusin myös tällä projektilla koetella tekoälyn hyödyntämisen eettisiä rajoja julkaisutoiminnassa. Tässä kokeilussa käytin tekoälyä sisällöntuotannossa pyytäen sitä muotoilemaan uudelleen projektin omaa dataa dialogin vaatimien vastausten muotoon, osana käsikirjoitusprosessia. Sitten pyysin tekoälyä kääntämään dialogin portugaliksi. Käännettyä kieltä tarkastutin kyseistä kieltä taitavilla ihmisillä. Onko tässä prosessissa siis tekijänoikeus minulla ja projektin muilla pohjana olevan sisällöntuottajilla, vai tekoälyllä? EU:n AI Act (Asetus 2024/1689) ottaa kantaa lähinnä tekoälyn koulutukseen käytetyn materiaalin tekijänoikeuksiin, ei niinkään tekoälyn avulla omasta materiaalista tuotetun aineiston tekijänoikeuksiin (Peukert, 2024, s. 4–6). Tätä Peukert kritisoi artikkelinsa loppupäätelmässä toteamalla, että laki, joka hyödyttää pääasiassa lakimiehiä, ei ole hyvä laki (Peukert, 2024, s. 24–25) Entä kun tuotan portugaliksi käännettyä tekstiä puheeksi tekoälyn avulla? Tai tulkkaan muun kielistä puhetta portugalinkieliseksi puheeksi samojen avulla? Tai tunnistutan puhetta tekstiksi tekoälyn avustamana? Ihan selkeitä vastauksia näihin kysymyksiin ei taida vielä olla, mutta jos mietitään vaikka muita kirjoittajan apuvälineitä, niin kirjoitetun tekstin virheitä on jo pitkään korjailtu oikolukuohjelmien avulla. Missä vaiheessa sisällöntuotantoa avustavat toiminnot muuttuvat sisällöntuottajiksi? Vai sulautuvatko ne vain yleisesti hyväksytyiksi työkaluiksi oikoluvun tapaan?
Generatiivisen tekoälyn avulla voidaan tasoittaa tai korjata kielellisiä vajavaisuuksia ja haasteita, silloin kun puhutaan eri kieliä eikä välttämättä muuten ymmärretä toisiamme. Toivon ja uskon, että lähitulevaisuudessa nämä palvelut kehittyvät, jolloin varsinkin reaaliaikainen viestintä helpottuu erikielisillä ihmisillä. Kokeilun ajatuksena oli myös antaa esimakua siitä, miten digitaaliset tekoälyavusteiset työkalut voisivat tasoittaa kielellistä eriarvoisuutta ja eroja nyt ja tulevaisuudessa. Puhutaanhan Mosambikissa lukuisia kieliä ja niiden eri murteita (makua, tsonga, nyanja, sena, lomwe, chuwabo, ndau, tswa, swahili) virallisen portugalin lisäksi.
Kuuntele podcasteja
Valmiita podcasteja voi kuunnella Soundcloudissa. Kuuntele ensimmäinen jakso Introdução ao Projeto (avautuu Soundcloudiin).
Towards inclusive and practice-oriented teacher education (TIPOTE)
Towards inclusive and practice-oriented teacher education -hankkeen päätavoitteena on vahvistaa inklusiivisen pedagogiikan osaamista ja parantaa opettajankoulutusten laatua kahdessa opettajankoulutusta tarjoavassa korkeakoulussa Mosambikissa. Hanke on käynnistynyt 2024 ja se päättyy 2026. Projektia koordinoi Jyväskylän ammattikorkeakoulu ja rahoittaa Suomen ulkoministeriö osana Higher Education Partnership (HEP) -ohjelmaa.