
Suuret kielimallit tiedon omaksumisen apuvälineenä
Suurten kielimallien kehitys on yksi modernin tietotekniikan ja tekoälytutkimuksen merkittävimmistä saavutuksista. Nämä syväoppimiseen ja massiivisiin tekstiaineistoihin perustuvat keinoälyt ovat muuttaneet tapamme hakea ja omaksua tietoa. Keskustelevat tekoälybotit, kuten OpenAI-yrityksen kehittämä ChatGPT, ovat kehittyneet yksinkertaisista sääntöpohjaisista järjestelmistä oppiviksi neuroverkoiksi, jotka voivat tuottaa ihmismäistä tekstiä, vastata kysymyksiin ja auttaa monimutkaisessa päätöksenteossa. Nämä ominaisuudet tekevät suurista kielimalleista potentiaalisen apuvälineen myös tutkijalle: tekoälyn avulla voi nopeasti omaksua ja oppia uutta tietoa mistä tahansa aihepiiristä. (Jurafsky ja Martin 2023, Vaswani ym. 2017.)
Internetin hakukoneet ovat toki mahdollistaneet tehokkaan tiedonhaun jo useita vuosikymmeniä, mutta tekoälyn vahvuus hakukoneisiin verrattuna on tiedon tehokkaassa kommunikoinnissa: kielimalli kykenee tiivistämään, perustelemaan ja tarvittaessa myös yksinkertaistamaan tietoa juuri käyttäjän vaatimalle tasolle. Käyttäjä voi pyytää mallilta yleistajuisen vastauksen johonkin ongelmaan, tai vaihtoehtoisesti hän voi lisäkysymysten avulla sukeltaa ongelman yksityiskohtiin ja vaatia bottia jopa todistamaan sen esittämät väitteet.
Teoriassa tämä kuulostaa erinomaiselta. Mutta asiassa on yksi paha ongelma: tekoäly on toisinaan väärässä.
Suurten kielimallien tuottaman tiedon luotettavuus
Vaikka suuret kielimallit pystyvät keskustelemaan sujuvasti lähes mistä tahansa aiheesta, ne eivät ymmärrä tuottamaansa tekstiä samalla tavalla kuin ihmiset. Tämä puute luo haasteita erityisesti silloin, kun tekoälyltä odotetaan tarkkoja ja virheettömiä vastauksia yksityiskohtaisiin kysymyksiin. Botti kyllä aina vastaa, mutta ei ole itsestään selvää, että vastaus olisi oikein.
Kielimallien tuottaman tiedon luotettavuuteen vaikuttavat useat seikat. Ensinnäkin niiden koulutusdata saattaa sisältää virheellistä, vanhentunutta tai puolueellista tietoa, mikä heijastuu myös mallin antamiin vastauksiin. Toiseksi mallit eivät aina osaa erottaa faktaa mielipiteestä, vaan ne saattavat esittää epävarman tiedon vakuuttavasti, mikä voi johtaa käyttäjää harhaan. Malli saattaa myös sortua ”hallusinoimaan”: vastaus näyttää asiantuntevalta ja vakuuttavalta, mutta se on todellisuudessa virheellinen, epätarkka tai jopa täysin keksitty (Ji ym. 2023). Käyttäjän vastuulle jää arvioida, puhuuko tekoäly totta vai palturia.
Kaikessa tiedonhaussa on tietysti oltava lähdekriittinen, kuten esim. etsittäessä tietoa internetistä perinteisillä hakukoneilla. Tekoälyn tuottaman tekstin lähdekritiikki on kuitenkin vaikeampaa, koska mallit eivät yleensä kerro, mistä niiden jakama tieto on peräisin. Aina ne eivät tiedä sitä itsekään! Kielimallin ytimessä olevan neuroverkon painokertoimiin varastoitunutta tietoa kutsutaankin implisiittiseksi tiedoksi, koska sitä ei ole olemassa ohjelman muistissa rakenteellisessa muodossa, vaan tieto on hajautettuna mallin sisäisiin parametreihin. Kielimallin tuottamat vastaukset eivät myöskään aina ole deterministisiä, vaan toistamalla täsmälleen saman kysymyksen kahdesti, voi saada kaksi erilaista, jopa keskenään ristiriitaista vastausta (Mündler ym. 2024).
Tutkijalle tiedon heikko luotettavuus on paha ongelma. Jos haluaa esimerkiksi oppia uusinta tutkimustietoa vedystä ja sen tuottamisesta, ei suoraan pysty luottamaan ChatGPT-kielimallin antamiin vastauksiin. Tähän tarpeeseen Jyväskylän ammattikorkeakoulun gH2ADDVA-hankkeessa kehitettiin uusi tekoäly, jonka vetyasiantuntemukseen käyttäjä pystyy varauksetta luottamaan ja tarvittaessa tarkistamaan faktat kunkin vastauksen liitteenä olevista lähdeviitteistä.
Retrieval Augmented Generation (RAG) -menetelmä
RAG-menetelmä on tapa parantaa suuren kielimallin tuottaman tiedon luotettavuutta. Tässä tekniikassa kielimalli ei luota pelkästään koulutusdatasta opittuun implisiittiseen tietoon tuottaessaan vastauksia, vaan se etsii annettuun kysymykseen eksplisiittisiä vastauksia ulkoisista tietolähteistä, kuten tietokannoista tai internetistä. Näin voidaan parantaa mallin kykyä tuottaa luotettavampia ja kontekstuaalisesti tarkempia vastauksia erityisesti silloin, kun sen omassa sisäisessä tietovarannossa ei ole riittävästi ajantasaista ja relevanttia tietoa. (Lewis ym. 2020.)
Kuviossa 1 on esitetty RAG-menetelmän perusperiaate. Käyttäjä esittää kysymyksen, johon kielimalli etsii ensin vastauksia rajatuista tietolähteistä hakualgoritmin avulla. Näin löydetyt tiedot (tekstiotokset) tuodaan sitten osaksi mallin syötekehotetta, ja malli generoi niiden perusteella vastauksen, joka on sekä informatiivinen että ajantasainen. Näin voidaan myös estää ”hallusinaatioiden” syntyä, sillä malli joutuu perustamaan vastauksensa annettuihin tietolähteisiin (Shuster ym. 2021). Tekoäly myös mainitsee nämä lähdeviitteet osana antamaansa vastausta, mikä mahdollistaa käyttäjälle täsmällisen lähdekritiikin.
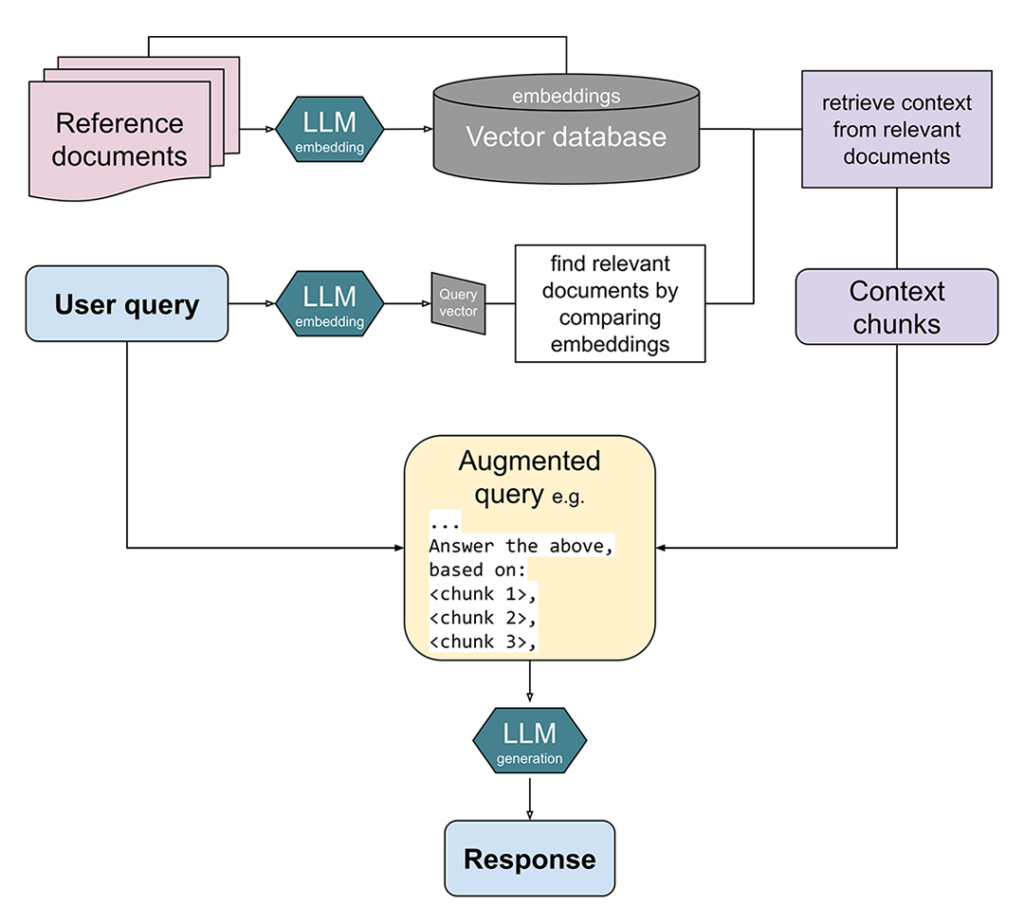
Vetyasiantuntija chatbot
Jyväskylän ammattikorkeakoulun gH2ADDVA-hankkeessa rakennettiin RAG-menetelmään perustuva tekoäly, joka perustaa antamansa vastaukset pelkästään vihreän vedyn tuotannon tieteellisiin julkaisuihin. Sovellus kehitettiin Microsoft Azure -pilvipalveluympäristössä hyödyntämällä Azure AI Foundry -alustan työkaluja. Pohjamalliksi valittiin GPT-35-turbo-16k -kielimalli eli tuttavallisemmin ChatGPT (vuonna 2022 julkaistu versio). Tähän kielimalliin integroitiin tiedonhakualgoritmi yllä olevan Kuvio 1:n mukaisesti. Tiedonhaku toteutettiin text-embedding-ada-002 -mallin semanttiseen upotukseen perustuvana vektorihakuna (OpenAI 2022). Tässä menetelmässä kukin sana, lause tai kappale kuvataan suuriulotteisen avaruuden vektoriksi, ja kahden tekstin merkitysten samankaltaisuutta mitataan niiden upotusvektoreiden välisen kulman avulla. Tämä on tavallista avainsanahakua hienostuneempi hakualgoritmi, koska se huomioi mm. synonyymit. Tietoaineistoksi valittiin 2000 tuoretta tutkimusartikkelia aihepiiristä ”Green hydrogen production”, ja tekoälyn odotettiin rajaavan vastauksensa RAG-menetelmän mukaisesti vain tähän lähdeaineistoon.
Alla olevat esimerkit osoittavat, että tuloksena saatu vetyasiantuntijabotti todella kykenee antamaan tarkempaa ja luotettavampaa tietoa vihreän vedyn tuottamisesta kuin pohjamallina käytetty ChatGPT ilman RAG-ominaisuutta (ja ilman internethakua). Näiden tekoälymallien asiantuntemusta vertailtiin esittämällä molemmille boteille Kuviossa 2 näkyvä kysymys: ”Mikä elektrolyysityyppi on kustannustehokkain vedyn tuotannossa?” ChatGPT-malli suosittelee PEM-elektrolyysia (Kuvio 3), mutta vetyasiantuntijabotti viittaa vuoden 2024 tutkimusartikkeliin (Rawan ym. 2024), jonka mukaan alkalielektrolyysi on yleensä kustannustehokkain (Kuvio 4). Jälkimmäinen botti mainitsee myös PEM-elektrolyysin varteenotettavana vaihtoehtona mutta ainoastaan uusiutuvien energialähteiden yhteydessä. Tekoälyt eivät siis ole tässä asiassa lainkaan samaa mieltä, mutta vetyasiantuntijabotin antama vastaus on nykytiedon valossa näistä kahdesta oikeampi ja täsmällisempi.



Edellä mainitussa testissä myös toistettiin Kuvion 2 kysymys ChatGPT:lle useita kertoja ja havainnoitiin vastausten koherenssia. Kävi ilmi, että tekoäly suosittelee välillä PEM-elektrolyysia ja välillä taas alkalielektrolyysiä. Tästä käy ilmi tiedon epävarmuus mallin sisäisessä tietovarastossa. Sen sijaan vetyasiantuntijabotti ei vaihda vastaustaan toistoissa, vaan se pitää johdonmukaisesti alkalielektrolyysia kustannustehokkaimpana lähteisiinsä vedoten.
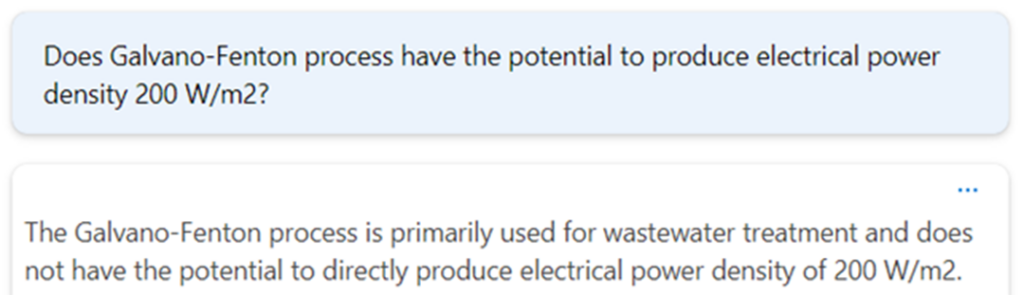
Toisessa testissä molemmille tekoälyboteille esitettiin Kuviossa 5 näkyvä kysymys: ”Mikä on sähkötehotiheyden potentiaali Galvano – Fenton -prosessissa?” Kuviossa 6 näkyy ChatGPT-mallin antama arvio: n. 1-10 W/m². Kuviossa 7 näkyy puolestaan vetyasiantuntijabotin antama arvio: n. 200 W/m² perustuen vuoden 2021 tutkimusartikkeliin (Gasmi ym. 2021). Tämä lähdeviite myös näkyy botin tuottamassa vastauksessa.



ChatGPT-mallia haastettiin vielä uudelleen kysymällä täsmällisemmin, onko Galvano – Fenton -prosessilla mahdollista saavuttaa 200 W/m² tehotiheys. Malli on itsepintaisesti sitä mieltä, että tämä on mahdotonta (Kuvio 8).
Osittain edellä esitetyt ChatGPT-mallin virheet selittyvät sillä, ettei sen koulutusdatassa ole syyskuuta 2021 uudempaa tietoa. RAG-menetelmän vaihtoehtona suurta kielimallia voitaisiinkin periaatteessa myös kouluttaa lisää täydentämällä koulutusdataa uusimmilla tutkimusartikkeleilla ja soveltamalla ns. fine-tuning menetelmää (Jeong 2024). Suuren mallin koulutus vaatii kuitenkin valtavasti laskentakapasiteettia, eikä tämä toimenpide poista sitä riskiä, että tekoäly täydennetystä aineistosta huolimatta päätyisi jakamaan epätarkkaa tietoa tai jopa ”hallusinoimaan”. Lisäkoulutus ei myöskään auttaisi mallia raportoimaan lähdeviitteitä vastauksiinsa eikä painottamaan hyväksyttyjä tutkimusartikkeleja luotettavampana tietolähteenä. Toki myös RAG-menetelmässä tekoälyn käyttämää ulkoista tietovarastoa on päivitettävä säännöllisesti, jotta mallilla olisi aina uusimmat tiedot käytettävissään, mutta tämä on huomattavasti kevyempi toimenpide kuin kielimallin kouluttaminen.
Huomattavaa on vielä, että uusimmat tekoälyavustajat, kuten GPT-4, DeepSeek, Gemini ja Copilot, osaavat hakea tietoa myös internetistä, jolloin koulutusdatan puutteet eivät yleensä nouse kriittiseen rooliin. Esimerkiksi GPT-4 selvittää Kuviossa 8 esitetyn haasteen virheettömästi, kunhan käyttäjä asettaa käyttöliittymässä asetuksen ”Search the web” aktiiviseksi (ilman tätä asetusta malli antaa virheellisen vastauksen). Internetistä löytyy kuitenkin tunnetusti myös väärää tietoa, joten internethaku ei välttämättä takaa mallin tuottaman vastauksen luotettavuutta kaikissa tilanteissa. Itse rakennetun RAG-tekoälyn hyvä puoli onkin siinä, että käyttäjä voi itse rajata tietovaraston juuri haluamallaan tavalla valiten mukaan esimerkiksi vain luotettavimmat tietolähteet.
Yhteenveto
RAG-menetelmä on tehokas ja melko yksinkertainen keino parantaa suuren kielimallin tuottaman tiedon luotettavuutta ja mahdollistaa täsmällisempää lähdekritiikkiä. Tätä menetelmää hyödynnettiin menestyksekkäästi Jyväskylän ammattikorkeakoulun gH2ADDVA-hankkeessa rakentamalla tekoäly, joka tuntee vihreän vedyn tuotannon uusimmat tutkimusartikkelit ja kykenee jakamaan niiden sisältämää tietoa käyttäjälle tehokkaasti ja luotettavasti.
Lisäarvoa uusilla vihreillä vetyteknologioilla energiantuotantoon, siirtoon ja hyödyntämiseen (gH2ADDVA)
Projektissa kehitämme uudistuvalle teollisuudelle puhtaita, ympäristöystävällisiä ja vaihtoehtoisia uusiutuvan energian tuotantomuotoja, uusia materiaaliteknisiä ratkaisuja sekä tekoälymenetelmiä ja -työkaluja arvoketjumallien luontiin. Projekti edistää osaltaan Suomen energiaomavaraisuutta ja yritysverkostoitumista sekä taklaa energian hinnan nousua.
Hankkeen kokonaisbudjetti on lähes 1,8 miljoonaa euroa. Projekti on Euroopan unionin osarahoittama oikeudenmukaisen siirtymän rahastosta (JTF). Projekti toteutetaan ajanjaksolla 1.1.2024 – 30.6.2026.
