
Generatiivinen tekoäly on tekoälyn alalaji, joka keskittyy uuden sisällön kuten tekstien, kuvien, tai videon luomiseen (Feuerriegel ym., 2024). Generatiivinen tekoäly pohjautuu tyypillisesti syväoppimiseen, missä erilaisia malleja opetetaan koulutusdatan perusteella (Hoffman ym., 2021; Salakhutdinov, 2015). Voimakkaasti viime vuosina esillä ollut ChatGPT edustaa yhtä generatiivisen tekoälyn tyyppiä, laajaa kielimallia (LLM), tai tarkemmin ilmaistuna Generative Pre-trained Transformer (GPT; vapaasti suomennettuna ”generatiivinen esikoulutettu muuntaja) – mallia (Radford ym., 2018). Laajan kielimallin, tai GPT:n, kehitykseen on voitu käyttää opetusdatana esimerkiksi kirjallisuutta, tutkimusartikkeleja, verkkosisältöä kuten Wikipediaa ja sosiaalista, sekä asiantuntijoiden ohjausta.
Tyypillisesti generatiivinen tekoäly, sekä myös laajat kielimallit pohjautuvat todennäköisyyksiin luodessaan esimerkiksi tekstiä (Vaswani ym., 2017). Käyttäjän kehotetta (eng. Prompt), mikä voi olla esimerkiksi chat-ikkunaan esitetty kysymys, verrataan kielimallin oppimaan tietoon ja rakenteisiin. Kehittyneet kielimallit kykenevätkin luomaan hämmentävän johdonmukaisia vastauksia kysymyksiin, jotka ovat semanttisesti ja kontekstuaalisesti johdonmukaisia.
Laajat kielimallit eivät kuitenkaan kykene laajentamaan oppimaansa, ellei niitä esimerkiksi kouluteta uudelleen tai yhdistä jonkinlaiseen hakuteknologiaan, esimerkiksi internet-selaimeen tai dokumentaatioon. Mallin kyvykkyyden laajentamisesta voikin olla hyötyä esimerkiksi tilanteissa, joissa sen halutaan hyödyntävän tietoa, jota siihen ei ole opetettu kuten organisaation sisäistä materiaalia. Yksi kyvykkyyttä laajentava hakumenetelmä on Retrieval-Augmented Generation (RAG; vapaasti suomennettuna ”hakutehostettu generointi”, Lewis ym., 2020). RAG-ratkaisun tarkoituksena on pystyä yhdistämään esimerkiksi organisaation dokumentaatiota kielimallin luovaan kyvykkyyteen. Yksinkertaisimmillaan RAG-ratkaisun pystyy toteuttamaan hyvin pienillä teknisillä kyvyillä, ja se toimii käyttötarkoituksen lisäksi hyvänä keinona tutustua generatiivisen tekoälyteknologian taustaan pintaa syvemmältä.
RAG-mallin toiminta perustuu pitkälti vektoriavaruuteen ja semanttiseen samankaltaisuuteen (Lewis ym., 2020). Kun tekstiä muutetaan numeerisiksi vektoriarvoiksi koulutuksen aikana, samantyyppiset sanat ja lauseet sijoittuvat vektoriavaruudessa lähelle toisiaan. Tämä mahdollistaa sen, että käyttäjän kysymystä voidaan verrata dokumentaation sisältöön vertaamalla niiden vektoriarvoja. Mitä lähempänä vektoriarvot ovat toisiaan, sitä samankaltaisempia tekstit ovat semanttisesti – eli niillä on samankaltainen merkitys. Näin RAG-malli pystyy löytämään käyttäjän kysymykseen liittyvät olennaisten tekstikatkelmien representaatiot laajasta dokumentaatiosta ilman, että dokumentaatiota tarvitsee käydä läpi manuaalisesti.
Esimerkkinä yksinkertainen RAG-ratkaisu
RAG-ratkaisun voi toteuttaa käyttämällä erilaisia verkkorajapintoja, paikallisia ratkaisuja tai näiden yhdistelmiä. Seuraavaksi kuvaan Python-kielellä rakennettua menetelmää, joka perustuu yhdistelmäratkaisuun (kuva 1). Tässä ratkaisussa PDF-muotoisesta dokumentaatiosta luodaan paikallinen, vektoriavaruuteen perustuva tietokanta Bidirectional Encoder Representations from Transformers (BERT; vapaasti suomennettuna ”kaksisuuntainen transformer-arkkitehtuuriin pohjautuva enkooderi”, ks. Virtanen ym., 2019) mallilla. Tästä tietokannasta haetaan tietoa käyttäen Facebook AI Similarity Search (FAISS; vapaasti suomennettuna ”Facebook AI vastaavuushaku”, ks. Johnson ym., 2019) menetelmää, joka hakee tietoa samankaltaisuuksien perusteella. Haetut tiedot yhdistetään verkkorajapinnan avulla OpenAI:n ChatGPT-4-kielimalliin, jonka vastaukset esitetään käyttäjälle.
- Dokumenttien valmistelu
- Tekstit poimitaan PDF-tiedostoista käyttäen textract-pakettia.
- Teksti siistitään poistamalla erikoismerkit ja jaetaan kappaleisiin.
- Tekstikappaleet muutetaan vektoriarvoiksi käyttämällä suomen kieleen erikoistunutta BERT-mallia.
- Vektoriarvojen indeksointi
- FAISS-menetelmällä luodaan hakuindeksi, joka mahdollistaa samankaltaisuushaut.
- Tekstikappaleiden vektoriarvot syötetään FAISS-indeksiin.
- Käyttäjän kysymyksen käsittely
- Käyttäjä esittää kysymyksen.
- Kysymys muutetaan vektoriarvoksi.
- Kontekstihaku
- Kysymyksen vektoriarvo lähetetään FAISS-indeksille, joka etsii semanttisesti lähimmät tekstikappaleet.
- Haussa käytetään top-k-menetelmää, joka palauttaa esimerkiksi 10 parhaiten vastaavaa hakutulosta.
- Kehotteen rakennus ja vastauksen generointi
- Hakutulokset, systeemikehote ja käyttäjän kysymys yhdistetään kehotteeksi.
- Kehote lähetetään rajapinnan kautta OpenAI:n ChatGPT-4-kielimallille.
- ChatGPT-4 muodostaa vastauksen hyödyntäen omaa tietämystään ja sille tarjottua kontekstia (hakutuloksia).
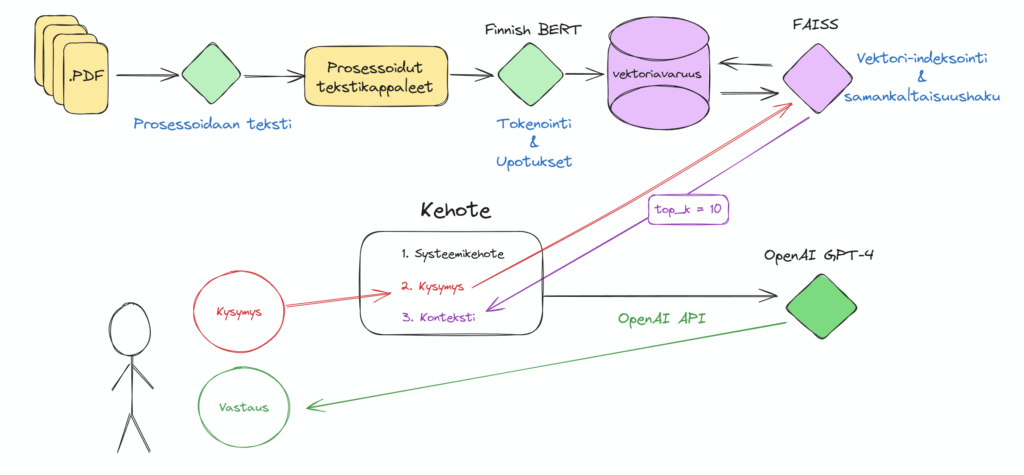
Sama ratkaisu löytyy myös avoimesta GitHub-repositiosta (Merilehto, 2024). Esimerkkiratkaisun datana käytin avoimesti saatavilla olevaa Keski-Suomen hyvinvointialueen palveluiden myöntämiskriteereitä. Prosessin aikana tekstin puhdistus sekä jakaminen kappaleisiin oli tärkeää – on parempi, että hakutuloksista noudetaan kokonaisia kappaleita eikä vain lauseita. Tällöin osumat olivat huomattavasti relevantimpia, ainakin tämän esimerkin osalta.
Kehoite ja vastaukset
Systeemikehote on RAG-malleja luotaessa tärkeä, sillä sen avulla kielimallille voidaan antaa yleisohjeet, joita se noudattaa. Tässä tapauksessa ”Olet Keski-Suomen hyvinvointialueen tekoälyassistentti. Käytössäsi on joitakin hyvinvointialueen dokumentteja, joista saat olennaista sisältöä mitä käyttää vastauksessasi. Sisällöt:” jonka jälkeen kehotteessa olisi FAISS-haun yhteydessä tulleet tulokset, ja tämän jälkeen käyttäjän kysymys. Listaus 1 näyttää esimerkin, missä on käyttäjän kysymys, liitetty systeemikehote, ja listan ensimmäinen konteksti.
Listaus 1 Kehotteen rakentuminen
Enter question (q to quit): Mitkä ovat kotihoidon palvelujen myöntämisen kriteerit?
Prompt for GPT-4: Olet Keski-Suomen hyvinvointialueen tekoälyassistentti. Käytössäsi on joitakin hyvinvointialueen dokumentteja, joista saat olennaista sisältöä mitä käyttää vastauksessasi. Sisällöt:
Context 1: suuruisen yhteenlasketun summan alle, pariskuntien kohdalla edellä mainittu tuloraja lasketaan kaksinkertaisena asiakkaan avuntarve on suurempi kuin hänen oma näkemyksensä avuntarpeesta sairaudentunnottomuus asiakas on omaishoidontuen piirissä jataa asiakkaan läheisen jaksamista on tarkoituksenmukaista tukea kotihoidon palveluilla. alueella ei ole yksityisiä palveluntuottajia, joille asiakkaan voi siirtää.
Tehokas kielimalli, kuten tässä tapauksessa GPT-4, ymmärtää suhteellisen hyvin, milloin kyseessä on konteksti mikä on olennainen kysymykseen vastaamisessa. On kuitenkin tärkeää, että hakujärjestelmä rakennetaan ja testataan toimimaan siten, että se tuo mahdollisimman olennaista tietoa kielimallille. Listauksessa 2 näkyy esimerkki hyvin onnistuneesta kontekstista.
Listaus 2 Konteksti-osio
Context 7: 7.4 Säännöllinen kotihoito Kotihoidon palvelujen alkaessa asiakkaan toimintakykyä, kuntoutumisen mahdollisuutta ja kotona selviytymistä seurataan ja tuetaan moniammatillisen tiimin toimesta ensimmäiseen palvelupäätökseen kirjatun kuntouttavan arviointijaksonmääräaikaisen jakson ajan. Jakso kestää yleensä noin 4-6 viikkoa, ja sen päättyessä arvioidaan tarve kotihoidon palvelujen jatkamiselle. Arvioinnin tehdään yhdessä asiakkaan sekä hänen läheistensä kanssa hyödyntäen ikääntyneiden palvelujen moniammatillista osaamista, sekä toimintakyvyn arviointi- ja seurantajärjestelmää RAI.
RAG-mallin merkittävin etu on sen kyky yhdistää laajojen kielimallien kyky tuottaa luonnollista kieltä organisaation oman dokumentaation sisältöön. Tämä mahdollistaa sen, että malli pystyy vastaamaan kysymyksiin ja ratkaisemaan ongelmia perustuen sekä yleiseen tietämykseensä että organisaatiokohtaiseen tietoon. Malli pystyy siis tuottamaan räätälöityjä vastauksia, jotka ovat linjassa organisaation käytäntöjen ja dokumentaation kanssa. Listaus 3 osoittaa, että tällainen yksinkertainenkin esimerkki pystyy tuottamaan suhteellisen oikeassa linjassa olevan vastauksen.
Listaus 3 RAG-mallin tuottama vastaus
Ikääntyneiden kotihoidon palvelun myöntämisen kriteerit pohjautuvat asiakkaan toimintakykyyn, hänen selviytymiseensä kotona, sekä hänen tarvitsemiensa palvelujen ja tukitoimien tarpeeseen. Kriteerejä, joita Keski-Suomen hyvinvointialueella noudatetaan kotihoidon palvelujen myöntämisessä, voi hahmottaa seuraavasti perustuen edellä mainittuihin dokumentteihin:
1. Toimintakyvyn arviointi: Asiakkaan toimintakykyä ja kuntoutumisen mahdollisuutta seurataan ja tuetaan moniammatillisen tiimin toimesta. Arviointi voi perustua esimerkiksi iRAI HC osittais- tai kokonaisarvioinnille ja muille RAI-järjestelmän mittareille.
2. Säännöllisen avun tarve: Palvelujen myöntämiseen vaikuttaa, jos asiakkaan avuntarve on säännöllistä ja suurempaa kuin hänen oma näkemyksensä avuntarpeesta, mikä voi sisältää esimerkiksi sairaudentunnottomuuden.
3. Omaishoidontuki: Asiakas voi olla omaishoidontuen piirissä, ja kotihoidon palvelut voivat olla tarkoituksenmukaisia tukemaan omaisen jaksamista.
4. Yksityisten palveluntuottajien puute: Alueella ei välttämättä ole yksityisiä palveluntuottajia, joihin asiakas voitaisiin ohjata, jolloin kotihoidon palvelujen tarjoaminen tulee ajankohtaiseksi.
5. Kodinhoidollisten tehtävien tukeminen: Kun asiakkaalla on avuntarvetta vain kodinhoidollisissa tehtävissä, ensisijaisena tavoitteena on asiakkaan itsenäisen tekemisen ylläpitäminen, lähipiirin tuen etsiminen tai yksityisen palveluntuottajan hankkiminen. Jos nämä keinot eivät ole riittäviä tai mahdollisia, kotihoidon aloittaminen voi tulla kyseeseen.
6. Yksilöllinen palvelutarve: Arvioinnissa huomioidaan asiakkaan yksilöllinen palvelutarve ja tukeminen palveluiden suunnittelussa.
Esimerkiksi, ympärivuorokautisen palveluasumiseen oikeutetut ikääntyneet asiakkaat, joilla kotona asuminen ei ole turvallista huolimatta tukitoimista, voivat olla oikeutettuja kotihoidon palveluihin kunnes päätös palveluasumisesta on tehty. Kotihoidon palvelut voidaan myöntää asiakkaan yksilöllisen tarpeen ja kriteerien täyttymisen perusteella.
RAG-mallin rajoitteena on, että sen tuottaman vastauksen laatu riippuu vahvasti saatavilla olevan dokumentaation kattavuudesta ja laadusta. Jos dokumentaatio on puutteellista tai vanhentunutta, myös mallin vastaukset voivat olla epätarkkoja tai harhaanjohtavia. RAG-malli ei myöskään pysty välttämättä päättelemään asioita, joita ei ole eksplisiittisesti mainittu dokumentaatiossa – tai se saattaa hallusinoida eli luoda ei-paikkaansa pitävää tietoa puuttuvan tiedon tilalle. Tyypillisesti RAG-mallin etuihin kuitenkin kuuluu hallusinaation vähentäminen, sillä se tuo lisää tietoa kielimallille ja tukee sen vastaamisen kyvykkyyttä (Shuster ym. 2021; Ding ym. 2024).
RAG-malli yleistyvänä käytännön työkaluna
Potentiaalisia sovelluskohteita RAG-mallille voisi olla esimerkiksi yrityksen sisäinen tietämyksenhallinta ja tukipalvelut. Malli voisi auttaa työntekijöitä löytämään nopeasti vastauksia kysymyksiinsä perustuen yrityksen omiin ohjeistuksiin ja dokumentaatioon. Myös asiakaspalvelussa RAG-mallia voidaan hyödyntää vastaamaan yleisimpiin asiakkaiden kysymyksiin perustuen tuotteiden käyttöohjeisiin ja usein kysyttyihin kysymyksiin. RAG-mallin kyvykkyys kontekstuaaliseen tiedonhakuun ja luonnollisen kielen tuottamiseen tekee siitä monipuolisen työkalun erilaisiin tietointensiivisiin tehtäviin.
Yhteenvetona voidaan todeta, että generatiivinen tekoäly ja laajat kielimallit ovat mullistaneet tavan, jolla pystytään käsittelemään ja tuottamaan luonnollista kieltä. Erityisesti RAG-mallin kaltaiset ratkaisut, jotka yhdistävät laajojen kielimallien kyvykkyyden esimerkiksi organisaatiokohtaiseen tietoon, avaavat uusia mahdollisuuksia tietämyksenhallintaan. Tulevaisuudessa generatiivisen tekoälyn kehitys tulee todennäköisesti jatkumaan nopeana. Kielimallien koko ja suorituskyky kasvavat entisestään. Samalla mallien räätälöinti erilaisiin käyttötapauksiin helpottuu kehittyvien työkalujen ja menetelmien ansiosta.
Valtavan potentiaalisia kehityssuuntia ovatkin esimerkiksi multimodaaliset mallit, jotka pystyvät käsittelemään tekstin lisäksi kuvaa, ääntä ja videota (Wu ym., 2023), sekä vahvemmin kontekstitietoiset mallit, jotka pystyvät sopeuttamaan kielenkäyttöään dynaamisesti keskustelun ja vuorovaikutuksen aikana. Myös kielimallien läpinäkyvyyteen, selitettävyyteen ja eettisyyteen tullaan varmasti kiinnittämään yhä enemmän huomiota. Organisaatioiden sekä yksilöiden kannattaakin seurata tiiviisti alan kehitystä ja pohtia, miten ne voisivat hyödyntää generatiivisen tekoälyn mahdollisuuksia omassa toiminnassaan.